The SAPPAN consortium has been researching several different use cases for new detection methods, such as the
classification of phishing websites or algorithmically generated domains (AGDs). Both topics were tackled using deep neural
network classifiers, achieving good accuracy on training and validation data mostly based on the English language. In this
article, we use the aforementioned models to classify the *.ch domain space which was recently made public by the entity
managing the .ch and .li country-code top-level domains for Switzerland and Lichtenstein (switch.ch).
As switch.ch recently published the .ch-zonefile [1], we have access to a snapshot of all registered *.ch domains, including all the domains that may never have been configured to resolve to an IP, are not linked to by any websites or webservices and are thus not discovered by web-crawlers like Google.
Modern remote controlled malware (so called remote access toolkits, that are widely used by advanced persistent threats, APTs) communicates with its handler. This is called command and control (C2). In most cases the malware will contact a public rendezvous server or public proxy (e.g. a virtual private server on AWS) to obtain instructions from its handler in more or less regular intervals. This is called beaconing.
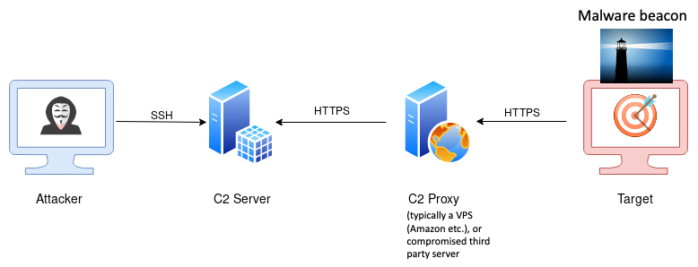
Since the malware communicates with its handler (the beaconing), the communication peer for this communication is a weak spot for the attacker. In the early days of malware development the communication peers used to be hardcoded and could easily be blocked. Nowadays domain generating algorithms that can reliably create domains from given input values (the seed values) are used, instead of hardcoded values. These algorithms work deterministically in the sense that a given input or seed value will always produce the same output domain:

If the malware operator uses the same algorithm and same seed values, the required domains can be registered ahead of time and the respective domains configured, to resolve to one or more C2 proxies. This approach makes it a lot more difficult to extract meaningful IOCs from captured malware samples and thus blacklist the corresponding malware traffic.
The complete setup looks as follows:
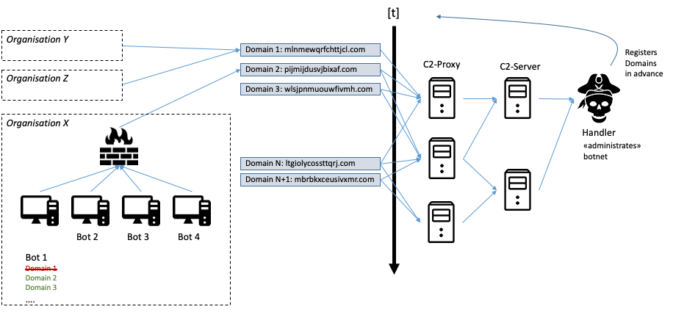
Many recently discovered threat actors have been using the abovementioned approach for their C2 communication. Examples are:
- The recently documented Flubot campaign, targeting Android devices, [2]
- The Solarwinds/Sunburst APT, [3]
Our goal is to find a self contained way for automatically identifying such suspicious domains in the .ch-zone almost exclusively based on information contained in the domain-name itself. For this we use the DGA detectors studied in SAPPAN.
In a first, naïve try we applied a model trained on global training data to classify the full 2.3 million domains found in the .ch-zonefile:
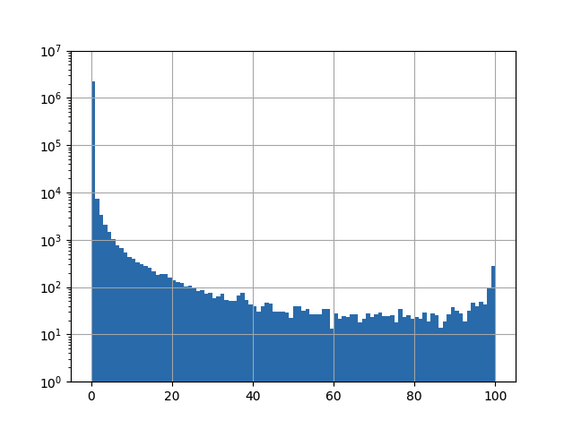
|
Bin |
Number of domains in bin |
|
[0,25) |
2257416 |
|
[25,50) |
1347 |
|
[50,75) |
675 |
|
[75,100] |
1024 |
The x-axis shows the classification certainty and the y-axis the number of domains that were classified in a certain bin regarding certainty.In order to do anything meaningful with these results, one has to pick a cutoff to create a shortlist of domains to be analyzed closer. Given above results, it is not possible to pick a feasible cutoff, because almost any cutoff will lead to a candidate list that is way too long.
A quick look at the results shows some interesting false positives, especially towards the end of the last bin (“feuerwehr” means fire brigade in German and the second to last line is a Swiss-german sentence):

By carefully enhancing the training data to intricacies of the public .ch-zonefile, it is however possible to improve the classification accuracy tremendously. To this end all .ch domains that had an MX-record in the zonefile were added to the benign training set and then the classifier was retrained. This leads to a much better distribution of the resulting classifications:
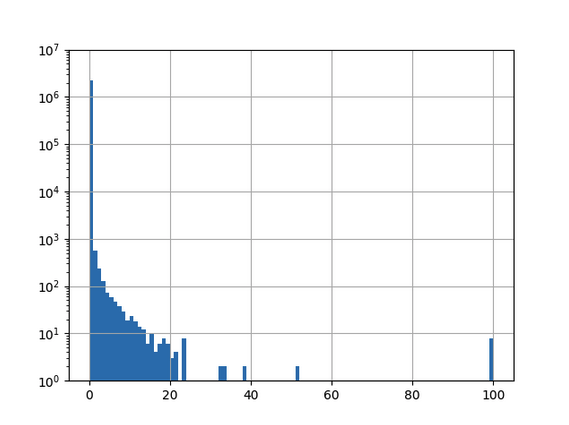
|
Bin |
Number of domains in bin |
|
[0,25) |
2260430 |
|
[25,50) |
13 |
|
[50,75) |
6 |
|
[75,100] |
13 |
Now all domains that get classified with a certainty of for example more than 50% can be examined manually.
We’ll leave it to the reader to take a look at the following, resulting candidate list:
|
Domain |
Certainity (model output) |
|
100% |
|
|
100% |
|
|
99.9% |
|
|
99.9% |
|
|
99.8% |
|
|
99.8% |
|
|
99.1% |
|
|
99.1% |
|
|
94.1% |
|
|
92.5% |
|
|
84.8% |
|
|
82.2% |
|
|
77.1% |
|
|
72.6% |
|
|
66.5% |
|
|
54.6% |
|
|
52.2% |
|
|
51.3% |
|
|
51.1% |
Conclusion:
Above method appears to work to identify a manageable number of suspicious domains (19 domains), from a very large dataset (2.3 million domains). There still appear to be false positives in this set but at the end of the day, this process of automatically identifying highly suspicious candidates and then manually investigating them is exactly what happens in security operation centers all over the world. Usually, however, with a much higher number of false positives and a much higher number of alerts.
One concern is, that 19 out of 2.3 million domains seems to be a rather low ratio of detections. This can be countered by lowering the classification threshold to lower percentages (below 50%) which in turn most likely would increase the number of false positives. In a production setting, the optimal detection threshold would have to be investigated further.
Given the results of manually inspecting the suspicious domains, we believe it would well be worth an analyst’s time to perform the manual analysis of domains that are detected in this way.
References:
[1]:
https://securityblog.switch.ch/2020/11/18/dot_ch_zone_is_open_data/
[2]: https://securityblog.switch.ch/2021/06/19/android-flubot-enters-switzerland/
[3]:
https://www.fireeye.com/blog/threat-research/2020/12/evasive-attacker-leverages-solarwinds-supply-chain-compromises-with-sunburst-backdoor.html
About the author(s):
Mischa Obrecht works as a cyber-security specialist in various roles for Dreamlab Technologies. He thanks Jeroen van Meeuwen (Kolabnow.com) and Sinan Sekerci (Dreamlab) for sharing their ideas, time and advice, while contributing to above research.
He also thanks Arthur Drichel from RWTH Aachen for sharing advice and an initial POC implementation of the convolutional neural network.