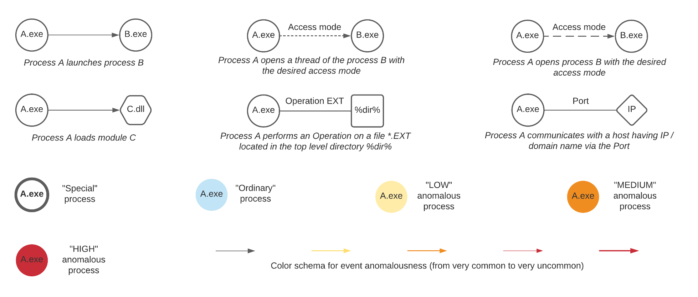
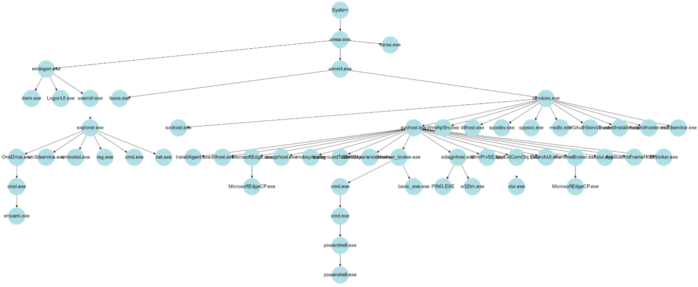
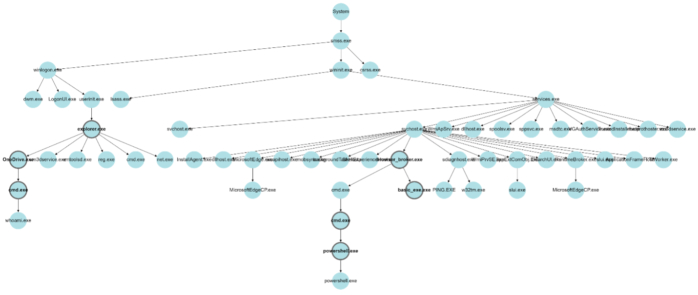
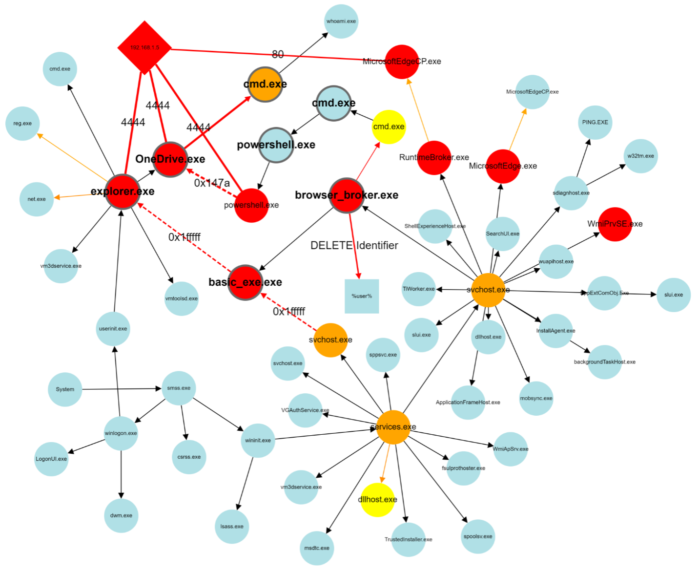
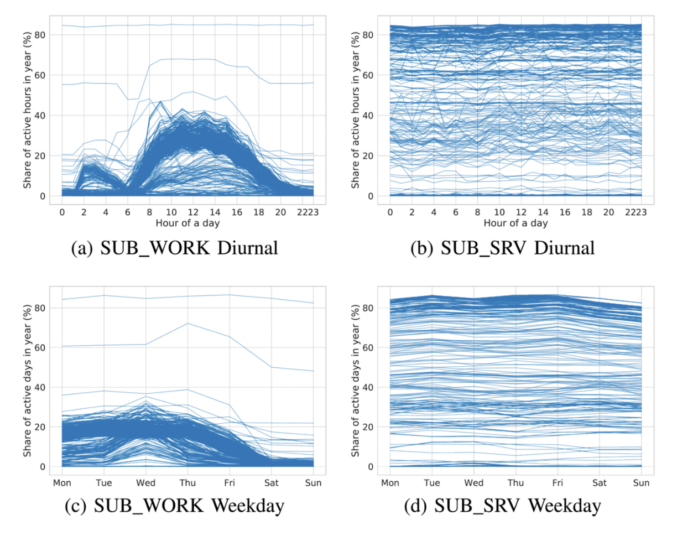
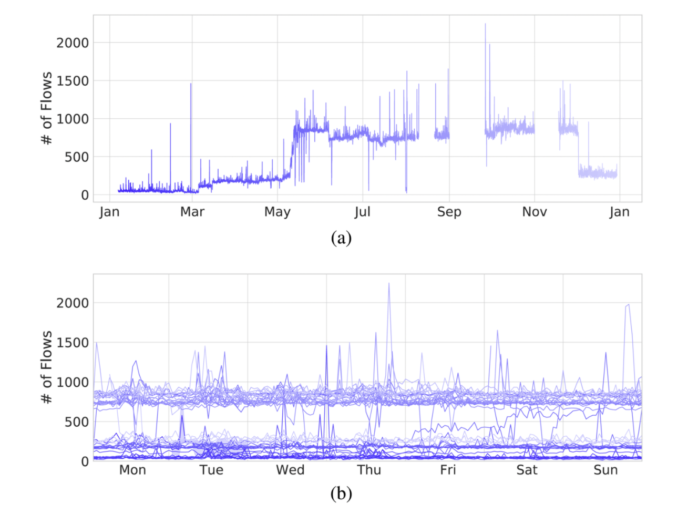
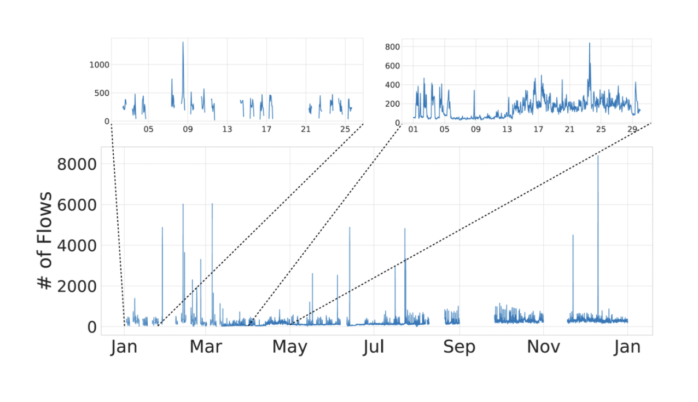
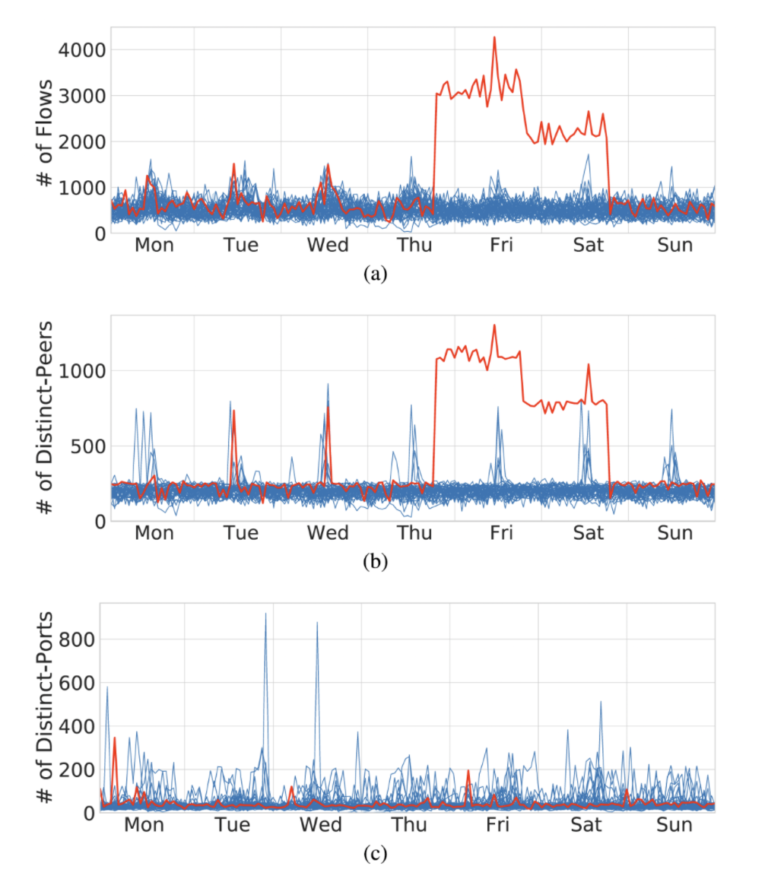
We are proud to announce the 4th International Workshop on Next Generation Security Operations Centers (NG-SOC 2022) to be held in conjunction with the 17th International Conference on Availability, Reliability and Security (ARES 2022 – http://www.ares-conference.eu) on August 23, 2022.
This year, the workshop is jointly organized by three projects that are funded by the European Commission: SOCCRATES, SAPPAN, and CyberSEAS.
Overview:
Organizations in Europe face the difficult task of detecting and responding to increasing numbers of cyber-attacks and threats, given that their own ICT infrastructures are complex, constantly changing (e.g. by the introduction of new technologies) and there is a shortage of qualified cybersecurity experts. There is a great need to drastically reduce the time to detect and respond to cyber-attacks. A key means for organizations to stay ahead of the threat is through the establishment of a Security Operations Center (SOC). The primary purpose of a SOC is to monitor, assess and defend the information assets of an enterprise, both on a technical and organizational level.
The aim of this workshop is to create a forum for researchers and practitioners to discuss the challenges associated with SOC operations and focus on research contributions that can be applied to address these challenges. Through cooperation among European projects, the workshop intends to provide a more comprehensive overview of the promising research-based solutions that enable timely response to emerging threats and support different aspects of the security analysis and recovery process.
DESCRIPTION OF THE PROJECTS
SOCCRATES will develop and implement a new security platform for Security Operation Centres (SOCs) and Computer Security Incident Response Teams (CSIRTs), that will significantly improve an organisation’s capability to quickly and effectively detect and respond to new cyber threats and ongoing attacks. The SOCCRATES Platform consists of an orchestrating function and a set of innovative components for automated infrastructure modelling, attack detection, cyber threat intelligence utilization, threat trend prediction, and automated analysis using attack defence graphs and business impact modelling to aid human analysis and decision making on response actions and enable the execution of defensive actions at machine-speed. The SOCCRATES Platform aims to enable organisations to improve the resilience of their infrastructures and increase productivity and efficiency at the SOC. The outcomes of the project will contribute to a more secure cyberspace and strengthen competitiveness in the EU digital single market.
More information: https://www.soccrates.eu/
SAPPAN project aims to enable efficient protection of modern ICT infrastructures via advanced data acquisition, threat analysis, and privacy-aware sharing and distribution of threat intelligence aimed to dynamically support human operators in response and recovery actions. The SAPPAN project will develop a collaborative, federated, and scalable attack detection to support response activities and allow for timely responses to newly emerging threats supporting different privacy-levels. We plan to identify a standard for the interoperable and machine-readable description of incident response reports and recovery solutions. The risk assessment, privacy, and security will be addressed in the standard design. Results of both attack detection and recovery and response processes will be shared on a global level to achieve an advanced response and recovery via knowledge sharing and federated learning. We develop a mechanism for sharing information on threat intelligence, which implements a combination of encryption and anonymization to achieve GDPR compliance. Novel visualization techniques will be developed to assist security and IT personnel and provide an enhanced content of context of the response and recovery and improved visual presentation of the process.
More information: https://sappan-project.eu/
CyberSEAS (Cyber Securing Energy dAta Services) project aims to improve the resilience of energy supply chains, protecting them from disruptions that exploit the enhanced interactions and extended involvement models of stakeholders and consumers in complex attack scenarios, characterised by the presence of legacy systems and the increasing connectivity of data feeds. The project has three strategic objectives: 1) countering the cyber risks related to highest impact attacks against EPES; 2) protecting consumers against personal data breaches and attacks; and 3) increasing the security of the Energy Common Data Space. CyberSEAS will deliver an extendable ecosystem of many customisable security solutions providing effective support for key activities, and in particular: risk assessment; interaction with end devices; secure development and deployment; real-time security monitoring; skills improvement and awareness; certification, governance and cooperation.
More information: https://cyberseas.eu/
For more information about the event, please check: https://www.ares-conference.eu/workshops-eu-symposium/ng-soc-2022/